5 years worth of Food Inspections in Chicago. I made some maps with CartoDB, using the data from data.cityofchicago.org
Results Pass vs. Fail

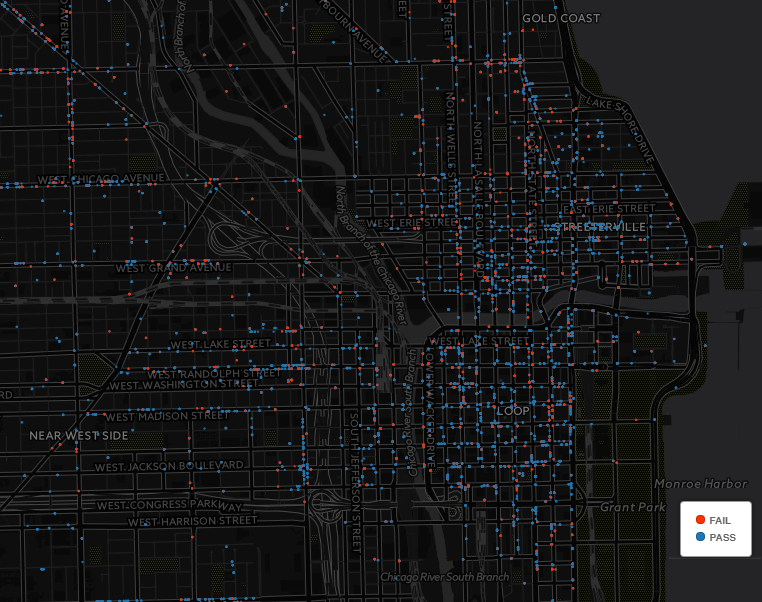
Results Pass vs. Fail (The Loop)
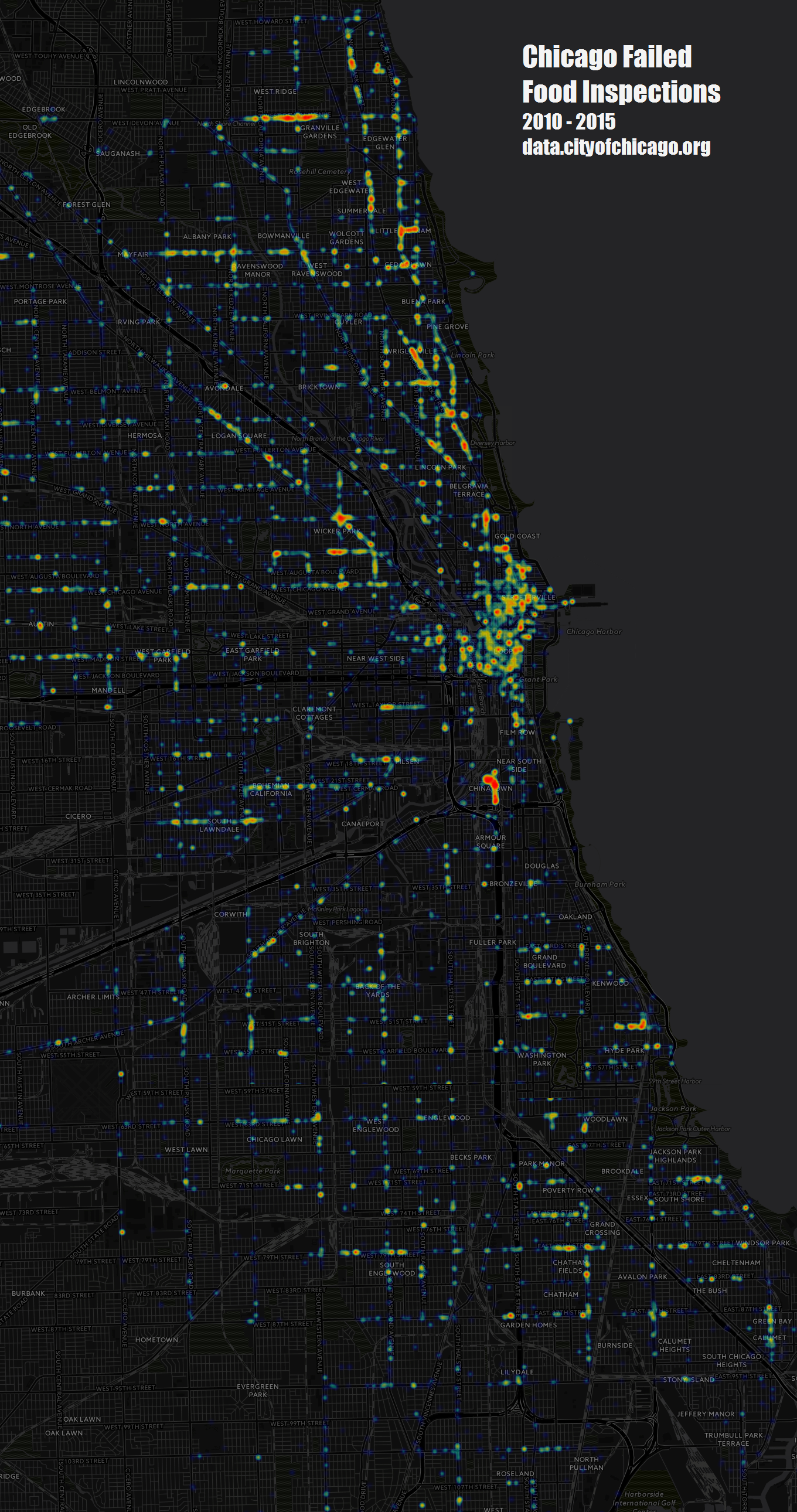
Fail Heatmap

5 years worth of Food Inspections in Chicago. I made some maps with CartoDB, using the data from data.cityofchicago.org
Results Pass vs. Fail
Results Pass vs. Fail (The Loop)
Fail Heatmap
A look into Chicago Police Department’s incident reports for marijuana related arrests.
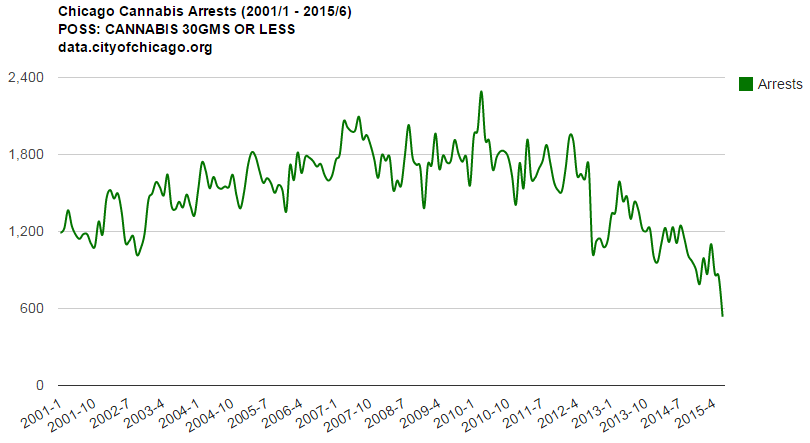
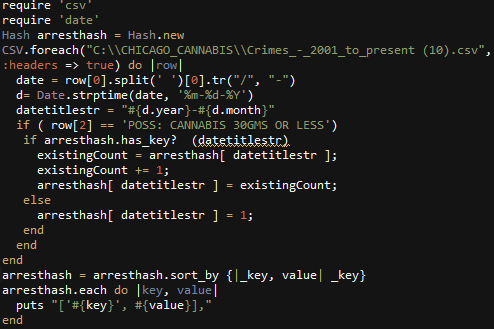
The chart below displays over 15 years of CPD’s Cannabis related arrests for possession of 30 grams or less. The data is from data.cityofchicago.org
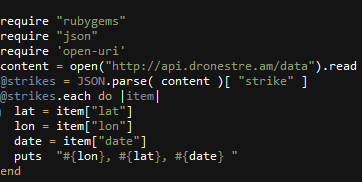
Here is the ruby code written to accumulate the monthly totals. Additional data filtering was done on the Socrata website prior to exporting the csv data file. Google Charts was used to create the line chart. CartoDB was used to create the still of the torque map.
Here is just over 12 years worth of San Francisco Police Department’s Drugs and Narcotics. Data is from data.sfgov.org.

This is a Torque map I made using CartoDB. 12 years in 20 seconds.
Exploring Iowa’s liquor sales. 2014-1 through 2015-2 Data Link

This dataset contains the spirits purchase information of Iowa Class “E” liquor licensees by product and date of purchase from January 1, 2014 to current. The dataset can be used to analyze total spirits sales in Iowa of individual products at the store level.
Totals by Category Name
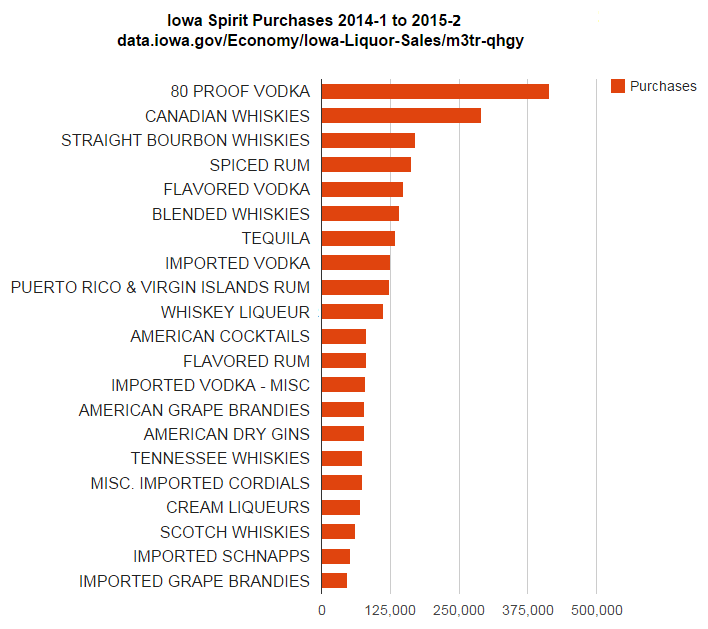
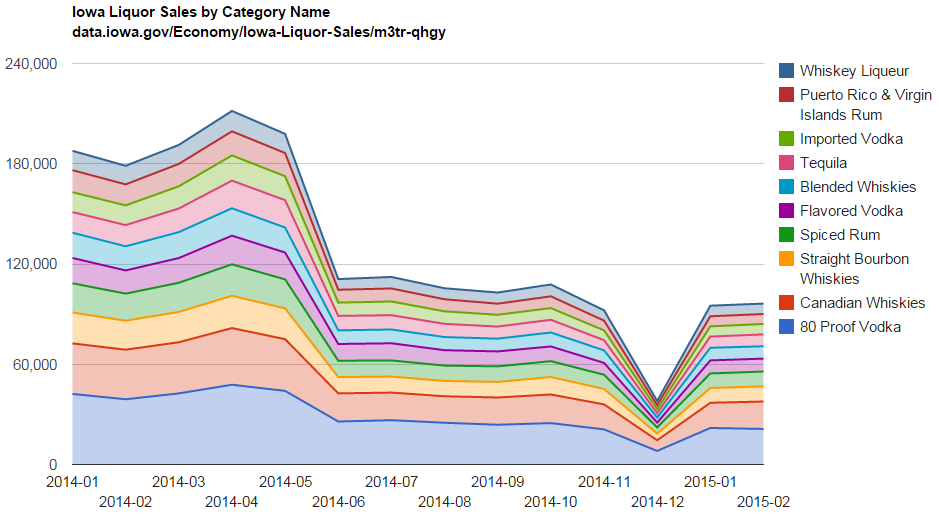
Totals by Category Name per Month
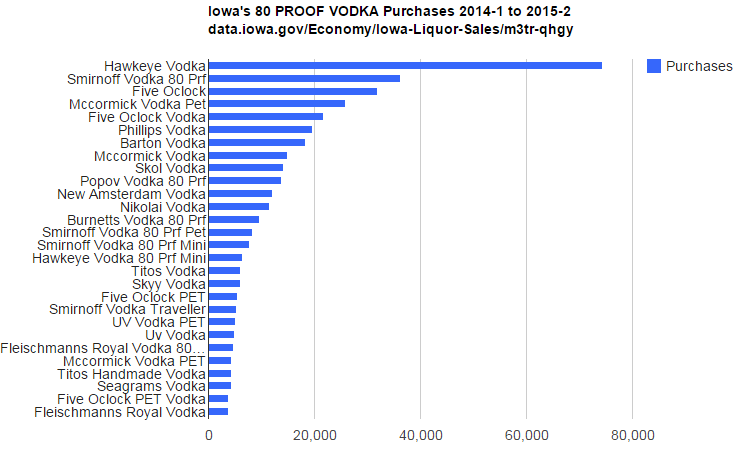
Iowa’s favorite 80 Proof Vodka Brands

A look into 15 years worth of prostitution through the eyes of the Chicago Police Department. The data is from data.cityofchicago.org. Time range includes years 2001 through 2015. CartoDB was used to create a Density, and Torque Map.
Density map
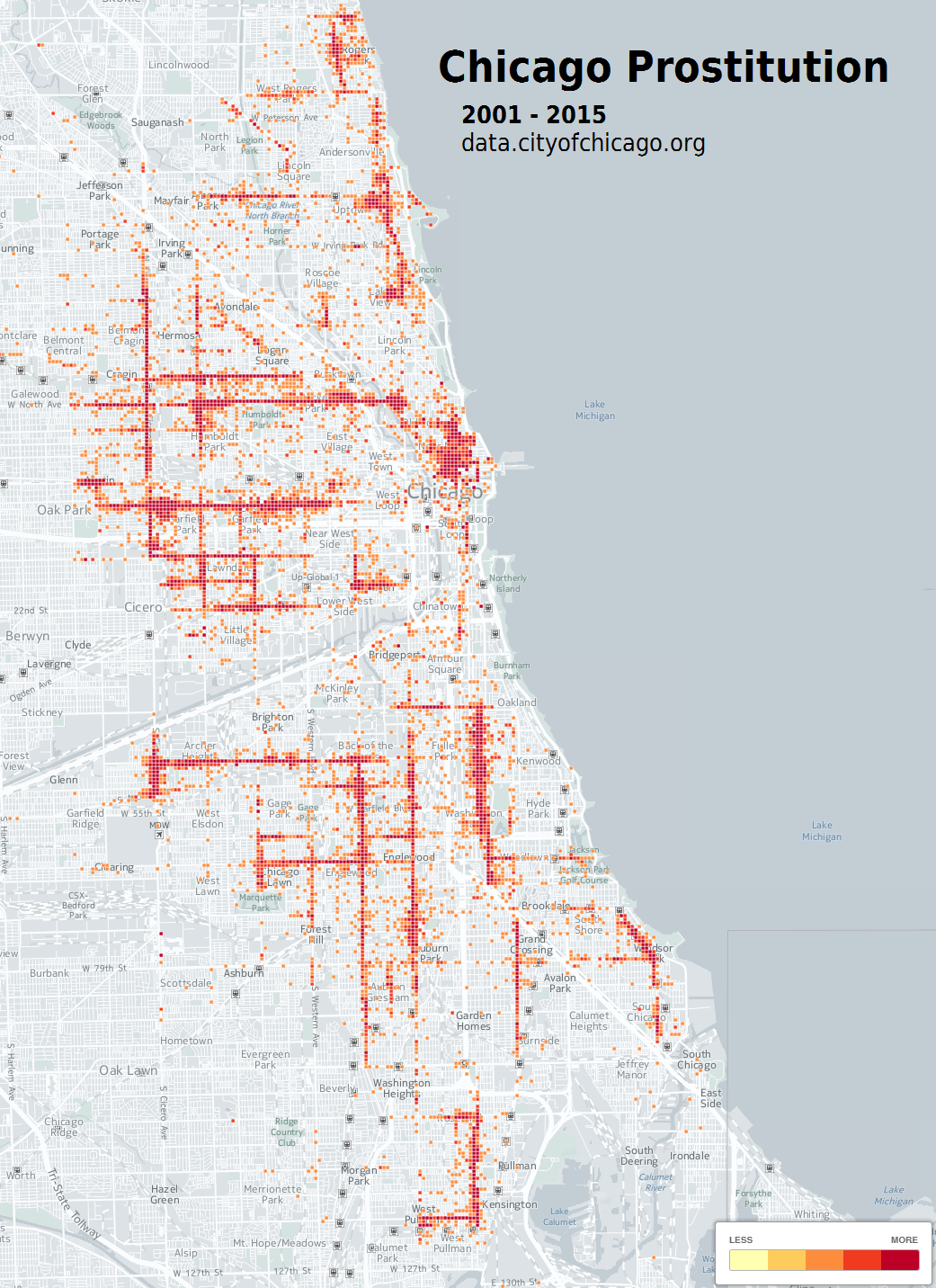
Geo-temporal map animation, 15 years in 10 seconds.
CartoDB + CPD narcotics incident reports.

2010 – 2015
Geo-temporal map of US Drone Strikes from the last 10 years.
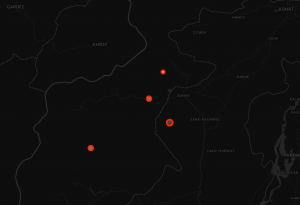
This is a revisit of an old post using different tools
Ruby was used to parse US Drone Strike API
CartoDB was used to render map
Camtasia was used to record animation
Ruby
In this post I will be exploring some data I found about the Vietnam War.
The data is from The National Archives Catalog

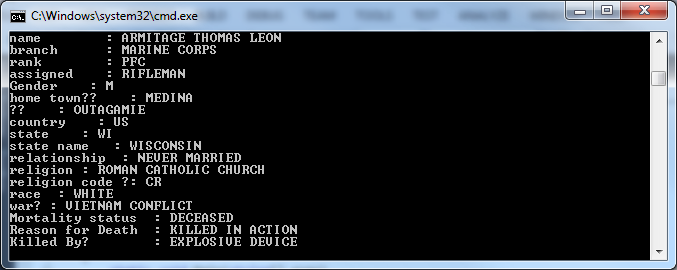
The downloaded data file DCAS.VN.EXT08.DAT contains 58,220 records. Each row appears to be an individual involved in the war. I couldn’t make immediate sense of the cookbook documents, so I proceeded straight to parsing it raw. By eyeballing the values of each column I was able to determine the following attributes per row:
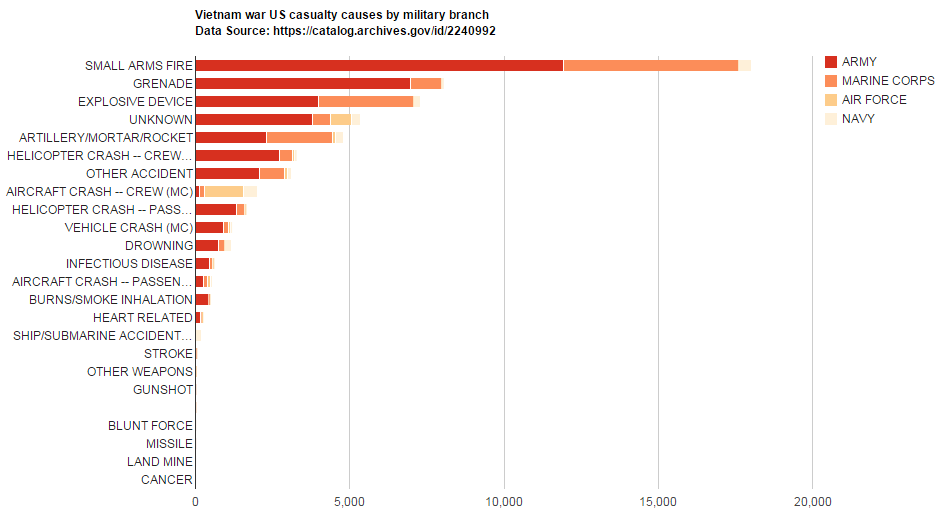
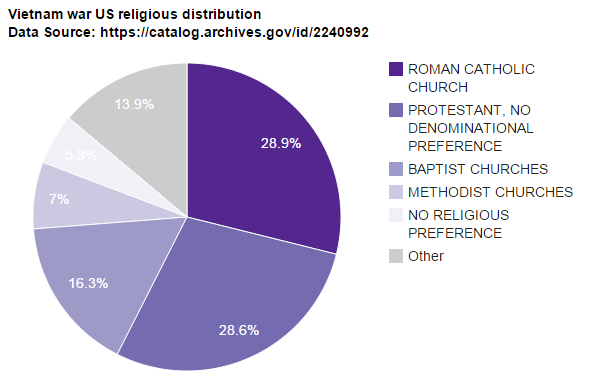
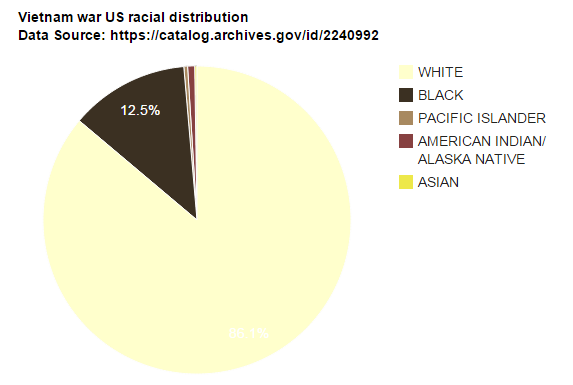
Name, Branch, Rank, Assigned Position, Gender, Hometown, Country, State, Relationship Status, Religion, Race, Mortility Status, and Reason of Death.
C# Console:
Console.BufferHeight = 4000; Console.WriteLine("Charlie in the Trees"); System.IO.StreamReader myFile = new System.IO.StreamReader(@"C:\VIETNAM\DCAS.VN.EXT08.DAT"); string vietnamData = myFile.ReadToEnd(); myFile.Close(); string[] lines = vietnamData.Split(new string[] { Environment.NewLine }, StringSplitOptions.None); int count = 0; foreach( string line in lines ) { string[] parts = line.Split('|'); Console.WriteLine("name : " + parts[4]); Console.WriteLine("branch : " + parts[6]); Console.WriteLine("rank : " + parts[7]); /* ... */ Console.WriteLine(); count += 1; } Console.WriteLine(); Console.WriteLine(); Console.WriteLine("total " + count); |
output
Alright, now that we’ve parsed the data, I typically ask myself these questions:
what is interesting?
what do I want to see?
what might be controversial?
what could invoke the attention of others?
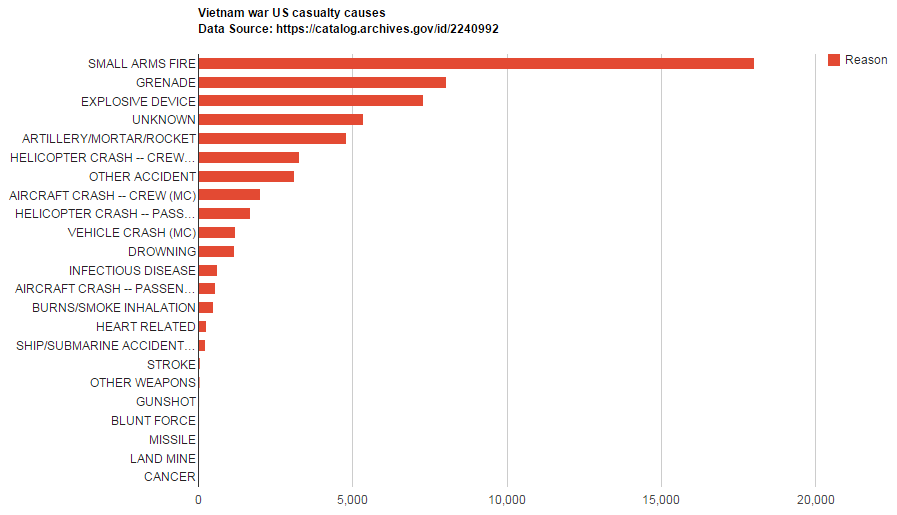
Dictionary<string, int> dictConcepts = new Dictionary<string, int>(); foreach( string line in lines ) { string[] parts = line.Split('|'); if (parts[43] == "DECEASED") { if (dictConcepts.ContainsKey(parts[45])) { int cur_count = dictConcepts[parts[45]]; cur_count += 1; dictConcepts[parts[45]] = cur_count; } else { dictConcepts.Add(parts[45], 1); } } } |
A Word Cloud of English words used within 430K Reddit usernames.
The data is from here. It was uploaded by reddit user Phycoz, in response to my previous post about Tumblr. Dictionary words searched and counted, were limited by greater than 4 characters in length. The same c# code from the previous post, Words used in Tumblr’s usernames (380,000 users) was used. Wordle for rendering the image.
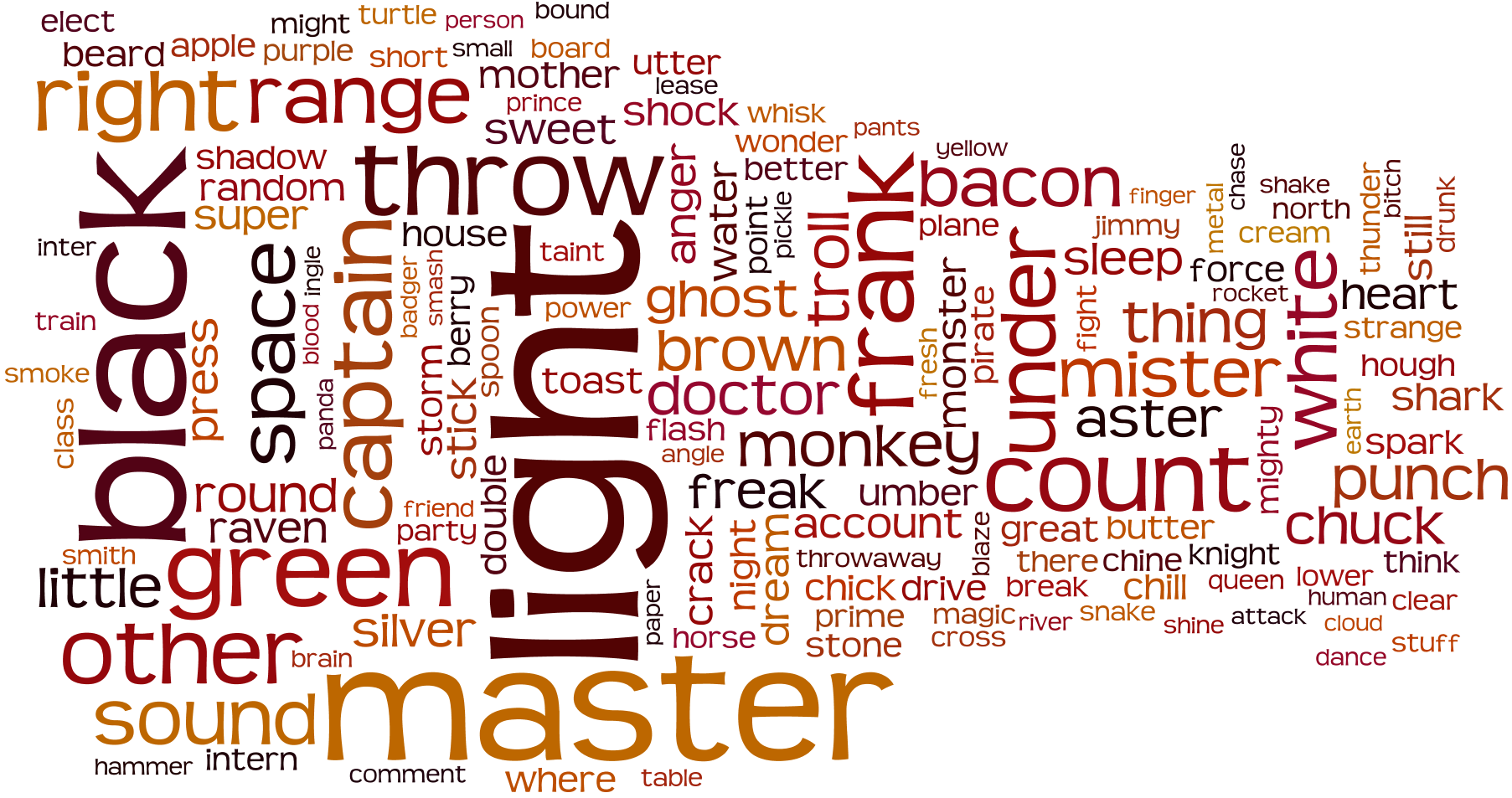
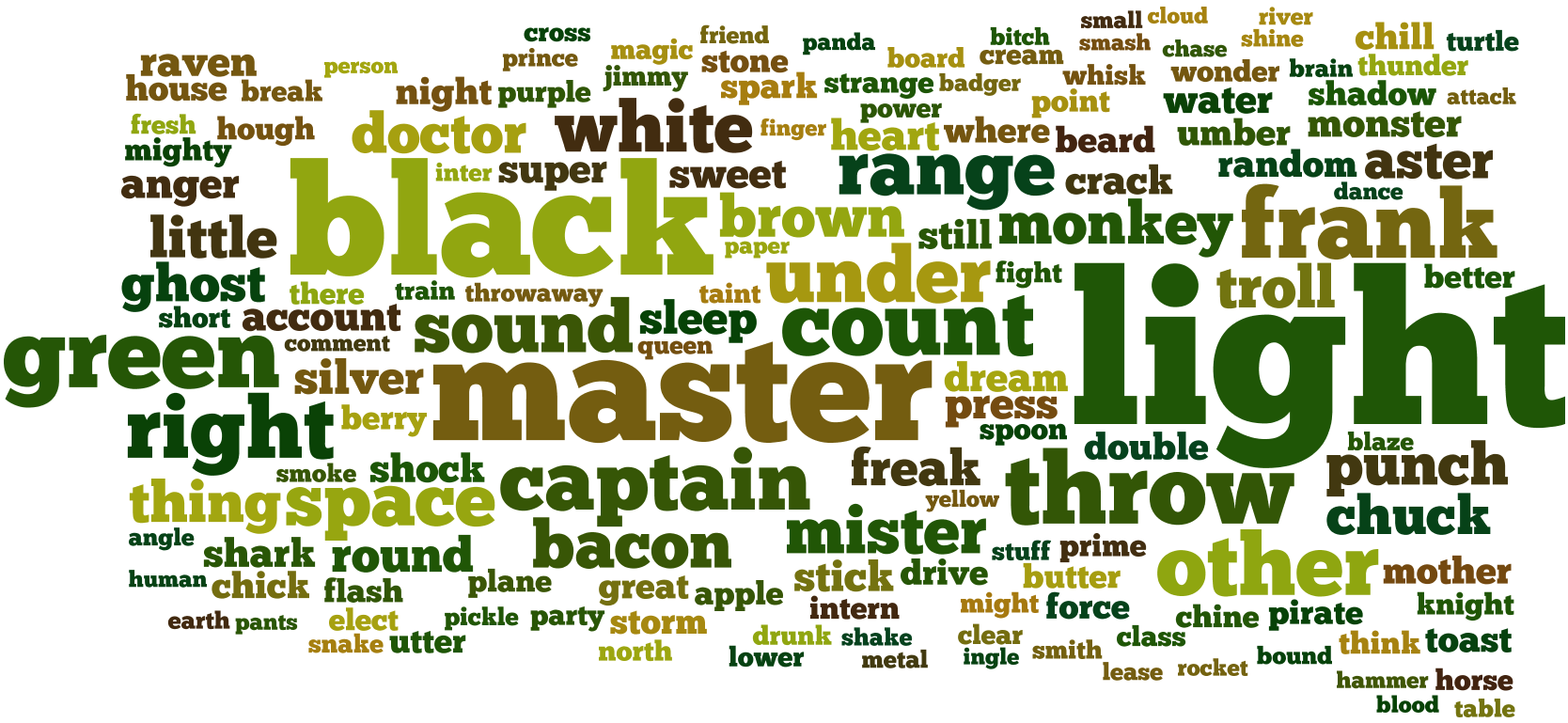
The data is a parse of 380,000 usernames. Link Here
C# was written to:
Most Frequent English Words Found in TUMBLR’s Usernames

Continue reading